


Blogs
A sustainable clothing choice by AI
Date
December 19, 2019
We built a database with 2000+ clothing brands with a sustainability rating. In this article, we walk you through the interesting parts of the process. This is how we help to make a sustainable choice in clothing. The code is available open source for you to explore and improve.

The fashion industry is impactful, let’s make it positive
Pollution, bad working conditions and animal welfare are unfortunately topics that are often pushed away by profit. This holds for the modern ‘fast-fashion’ industry which produces most of our clothes. Fortunately, some brands and initiatives are making an effort, but how do you know as consumer? Searching for information is very time consuming. Which is why we used scraping, artificial intelligence, natural language processing and explainability to provide more sustainable clothing information, faster than current approaches.
Our database will not be the answer to all the adverse effects of the ‘fast-fashion’ industry, but we hope to provide a piece of the sustainability puzzle.
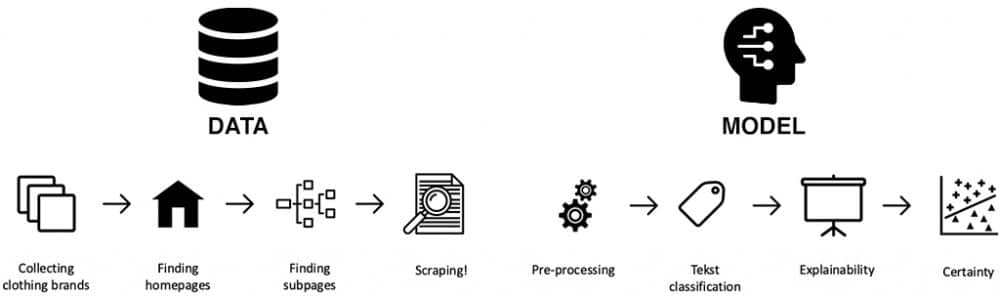
Models need data
Our process consisted of 2 main steps: gathering the data (crawling and scraping) and predicting the sustainability for each of these brands. We gathered 2000+ clothing brands plus their homepages using the Google Search API. To be able to build a supervised model, we also needed some examples of brands which are (not) sustainable. We collected ratings from a few initiatives that manually rate clothing brands based on their level of sustainability, such as Project Cece.
To keep our process efficient, we looked at a trade-off between speed and incorporating useful information. Therefore, we crawled through several levels of the clothing brand and selected the homepage +10 relevant pages based on a dictionary. These relevant pages included pages like about-us, history and blogs and excluded product pages, shopping carts and store locator. We used BeautifulSoup4 (Python) to obtain all information in the headers and paragraphs. As many brands do not have an English website, we used the Google Translator API to translate all non-English content.
Wordclouds with information

In the EDA (Explorative Data Analysis) stage, we already see some clear differences between data from ‘sustainable’ and ‘not-sustainable’ brands. These two word-clouds contain the most frequent words per class. We ignored words which occurred often at both classes, and we applied a little pre-processing, such as lower-casing and removing punctuation and stopwords. As can be seen in the word-clouds, there is a clear difference between the two classes. Interestingly, we mainly see brand names in the ‘not-sustainable’ word-cloud. Fortunately, the model does not train on the names of the specific brands, which we know trough explainability.
High accuracy achieved using SVM
To assign sustainability labels to clothing brands, we make use of supervised machine learning algorithms. After dividing our data into a training and hold out set, we kept improving our model using the results of 5-fold cross validation. We continued using the Linear SVC (Support Vector Machine) classifier, with tfidf-vectors of our data as its input, as this model performed best during cross validation. As shown in the table below, the accuracy is sufficiently high. One could argue that a metric punishing false negatives (‘sustainable’ brands classified as ‘non-sustainable’) even more, could be more appropriate.

Improving our model through explainability
We firmly believe in explainability, because you need to know why a certain brand is sustainable, while the other is not. ‘Just trust me’ is nothing compared to ‘trust me because...’.
Looking at the most important features in the image below, with a handy tool called Explain Like I’m 5, the ‘sustainable’ label is predicted correctly; however this prediction heavily relies on noise like ‘javascript’ and ‘cart’. We use this input to refine our pre-processing which does lead to more sensible weighing terms, at the cost of a slight decrease in model performance on the training set (0,814), while accuracy on the hold-out set remains the same.
Correct prediction for Patagonia. Using ELI5 to highlight the used important features for making this decision. Lots of noise in the first text snippet, like ‘account’, ‘javascript’, ‘cart’ etcetera. After refined pre-processing, the model chooses more logical important features.

Strong results by knowing the weakness
Building a 100% correct model is almost impossible. Besides using the output probability of the model, we came up with the idea of using Word2Vec embeddings to find brand neighbours. For each brand, we collected the 300 dimensional embeddings of the 100 most frequent words. Using these vectors, we can make two calculations:
- The distance between the vectors of a brand and the average vector of a class, and
- Checking the class of the brand that is closest, i.e. which brands are the neighbours of a given brand.
If the neighbours of an unlabelled brand are similar to the prediction, we trust the model. On the other hand, when a new brand is very different than the brands the model has ever seen before, we provide the ‘unknown’ class.
What you do today, can improve all our tomorrows
Would you like to know more?
Would you like to know more about sustainability and AI or this project? Get in touch with Julia van Huizen at jvanhuizen@adc-consulting.com, or check our contactpage.
Or get in touch to arrange a training tailored to your needs. We would be very happy if you share your thoughts, ideas and improvements. The open source code plus ideas for improvements can be found here.
Date
December 19, 2019
We built a database with 2000+ clothing brands with a sustainability rating. In this article, we walk you through the interesting parts of the process. This is how we help to make a sustainable choice in clothing. The code is available open source for you to explore and improve.
The fashion industry is impactful, let’s make it positive
Pollution, bad working conditions and animal welfare are unfortunately topics that are often pushed away by profit. This holds for the modern ‘fast-fashion’ industry which produces most of our clothes. Fortunately, some brands and initiatives are making an effort, but how do you know as consumer? Searching for information is very time consuming. Which is why we used scraping, artificial intelligence, natural language processing and explainability to provide more sustainable clothing information, faster than current approaches.
Our database will not be the answer to all the adverse effects of the ‘fast-fashion’ industry, but we hope to provide a piece of the sustainability puzzle.
Models need data
Our process consisted of 2 main steps: gathering the data (crawling and scraping) and predicting the sustainability for each of these brands. We gathered 2000+ clothing brands plus their homepages using the Google Search API. To be able to build a supervised model, we also needed some examples of brands which are (not) sustainable. We collected ratings from a few initiatives that manually rate clothing brands based on their level of sustainability, such as Project Cece.
To keep our process efficient, we looked at a trade-off between speed and incorporating useful information. Therefore, we crawled through several levels of the clothing brand and selected the homepage +10 relevant pages based on a dictionary. These relevant pages included pages like about-us, history and blogs and excluded product pages, shopping carts and store locator. We used BeautifulSoup4 (Python) to obtain all information in the headers and paragraphs. As many brands do not have an English website, we used the Google Translator API to translate all non-English content.
Wordclouds with information
In the EDA (Explorative Data Analysis) stage, we already see some clear differences between data from ‘sustainable’ and ‘not-sustainable’ brands. These two word-clouds contain the most frequent words per class. We ignored words which occurred often at both classes, and we applied a little pre-processing, such as lower-casing and removing punctuation and stopwords. As can be seen in the word-clouds, there is a clear difference between the two classes. Interestingly, we mainly see brand names in the ‘not-sustainable’ word-cloud. Fortunately, the model does not train on the names of the specific brands, which we know trough explainability.
High accuracy achieved using SVM
To assign sustainability labels to clothing brands, we make use of supervised machine learning algorithms. After dividing our data into a training and hold out set, we kept improving our model using the results of 5-fold cross validation. We continued using the Linear SVC (Support Vector Machine) classifier, with tfidf-vectors of our data as its input, as this model performed best during cross validation. As shown in the table below, the accuracy is sufficiently high. One could argue that a metric punishing false negatives (‘sustainable’ brands classified as ‘non-sustainable’) even more, could be more appropriate.
Improving our model through explainability
We firmly believe in explainability, because you need to know why a certain brand is sustainable, while the other is not. ‘Just trust me’ is nothing compared to ‘trust me because...’.
Looking at the most important features in the image below, with a handy tool called Explain Like I’m 5, the ‘sustainable’ label is predicted correctly; however this prediction heavily relies on noise like ‘javascript’ and ‘cart’. We use this input to refine our pre-processing which does lead to more sensible weighing terms, at the cost of a slight decrease in model performance on the training set (0,814), while accuracy on the hold-out set remains the same.
Correct prediction for Patagonia. Using ELI5 to highlight the used important features for making this decision. Lots of noise in the first text snippet, like ‘account’, ‘javascript’, ‘cart’ etcetera. After refined pre-processing, the model chooses more logical important features.
Strong results by knowing the weakness
Building a 100% correct model is almost impossible. Besides using the output probability of the model, we came up with the idea of using Word2Vec embeddings to find brand neighbours. For each brand, we collected the 300 dimensional embeddings of the 100 most frequent words. Using these vectors, we can make two calculations:
- The distance between the vectors of a brand and the average vector of a class, and
- Checking the class of the brand that is closest, i.e. which brands are the neighbours of a given brand.
If the neighbours of an unlabelled brand are similar to the prediction, we trust the model. On the other hand, when a new brand is very different than the brands the model has ever seen before, we provide the ‘unknown’ class.
What you do today, can improve all our tomorrows
Would you like to know more?
Would you like to know more about sustainability and AI or this project? Get in touch with Julia van Huizen at jvanhuizen@adc-consulting.com, or check our contactpage.
Or get in touch to arrange a training tailored to your needs. We would be very happy if you share your thoughts, ideas and improvements. The open source code plus ideas for improvements can be found here.
Talk to our experts
Let's create real impact together with data and AI

Manager, Agriculture & Food
Fleur Fok
Talk to our experts
Let's create real impact together with data and AI
Manager, Agriculture & Food
Fleur Fok